 WorldForge
WorldForgeWe showcase more interesting cases to demonstrate the capabilities of our project. For 3D scene generation, we include voyager experiences in non-realistic scenes such as Artworks, AIGC content, portrait photography, city walks, and more. For 4D video re-cam, we demonstrate camera arc rotation, local close-ups, outpainting, viewpoint transferring, and video stabilization. Additionally, we perform video editing tasks including object removal, object addition, face swapping, subject transformation, and try-on applications.
Recent video diffusion models demonstrate strong potential in spatial intelligence tasks due to their rich latent world priors. However, this potential is hindered by their limited controllability and geometric inconsistency, creating a gap between their strong priors and their practical use in 3D/4D tasks. As a result, current approaches often rely on retraining or fine-tuning, which risks degrading pretrained knowledge and incurs high computational costs. To address this, we propose WorldForge, a training-free, inference-time framework composed of three tightly coupled modules. Intra-Step Recursive Refinement (IRR) introduces a recursive refinement mechanism during inference, which repeatedly optimizes network predictions within each denoising step to enable precise trajectory injection. Flow-Gated Latent Fusion (FLF) leverages optical flow similarity to decouple motion from appearance in the latent space and selectively inject trajectory guidance into motion-related channels. Dual-Path Self-Corrective Guidance (DSG) compares guided and unguided denoising paths to adaptively correct trajectory drift caused by noisy or misaligned structural signals. Together, these components inject fine-grained, trajectory-aligned guidance without training, achieving both accurate motion control and photorealistic content generation. Extensive experiments across diverse benchmarks validate our method's superiority in realism, trajectory consistency, and visual fidelity. This work introduces a novel plug-and-play paradigm for controllable video synthesis, offering a new perspective on leveraging generative priors for spatial intelligence.
We propose a general inference-time guidance paradigm that leverages the rich priors of large-scale VDMs in spatial intelligence tasks, such as geometry-aware 3D scene generation and video trajectory control. Our method adopts a warping-and-repainting pipeline, in which input frames are warped along a reference trajectory and then used as conditional inputs in the repainting stage. Building on this, we develop a unified, training-free framework composed of three complementary mechanisms, each designed to address a specific challenge in trajectory-controlled generation.
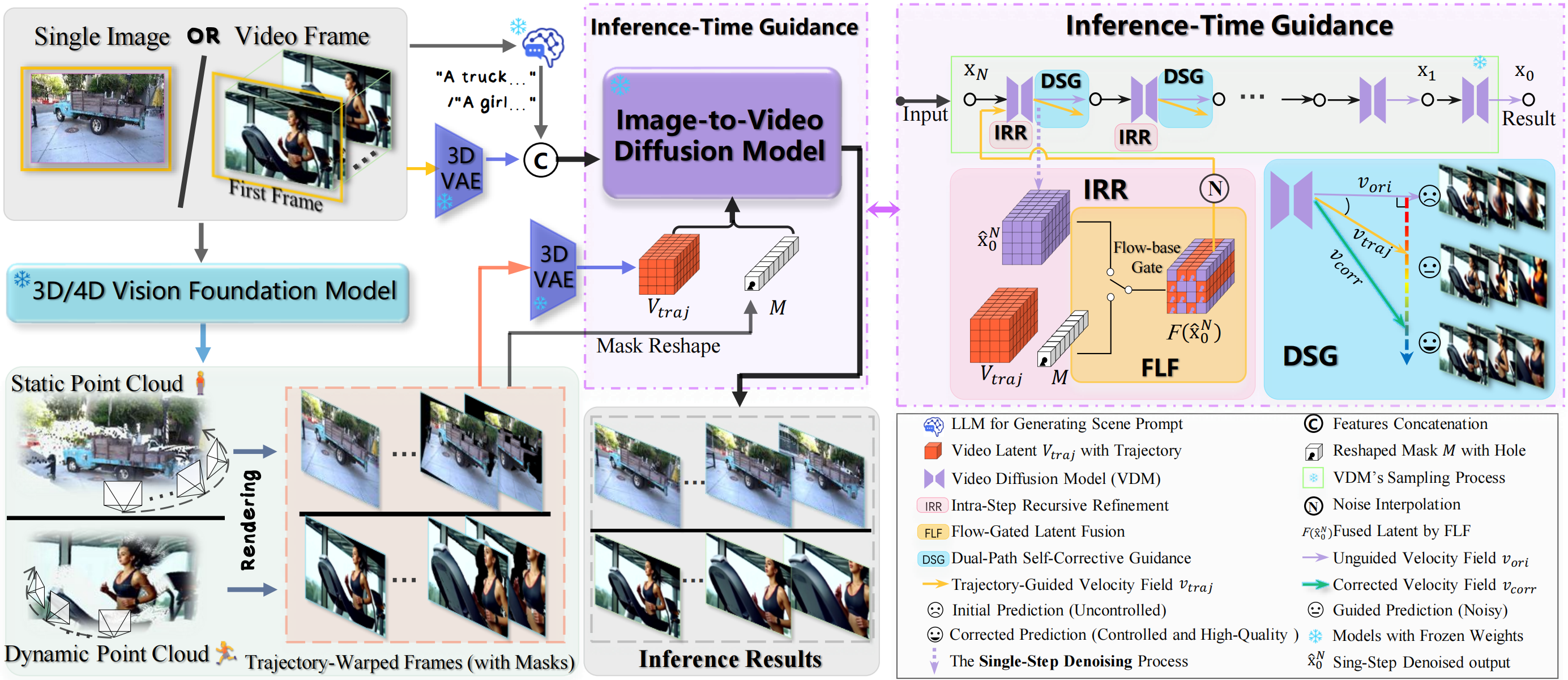
Given a single image or video frames, a vision foundation model reconstructs a scene point cloud, which is warped and rendered along a user-specified trajectory to produce a guidance video. The input image (or first frame) is also converted into a textual prompt and latent representation for an image-to-video diffusion model. Trajectory control is injected through a training-free strategy comprising IRR, FLF, and DSG, enabling precise control and high-quality synthesis without additional training.
3D Scene Generation from Single View: Compared to existing SOTA methods, our approach produces more consistent scene content under novel viewpoints, with improved image detail, trajectory accuracy, and structural plausibility.
Dynamic 4D Video Re-Cam: Comparison of 4D trajectory-controlled re-rendering. Baselines often produce implausible artifacts (e.g., flattened faces, floating heads), reflecting limited use of pretrained priors. Our inference-time guidance leverages these latent world priors to re-render realistic, high-quality content along the target trajectory. We compare against state-of-the-art baselines under identical inputs; for ReCamMaster (text-controlled), parameters are adjusted to match the target path.
Ablation of the proposed components. IRR enables trajectory injection; without it, the model defaults to prompt-only free generation, and FLF/DSG cannot be applied. FLF decouples trajectory cues from noisy content; removing it introduces noise from warped frames. DSG guides sampling toward high-quality, trajectory-consistent results; without it, detail and plausibility drop. The full model achieves the best fidelity and control, demonstrating their complementary effects.
@misc{song2025worldforgeunlockingemergent3d4d,
title={WorldForge: Unlocking Emergent 3D/4D Generation in Video Diffusion Model via Training-Free Guidance},
author={Chenxi Song and Yanming Yang and Tong Zhao and Ruibo Li and Chi Zhang},
year={2025},
url={https://arxiv.org/abs/2509.15130},
}